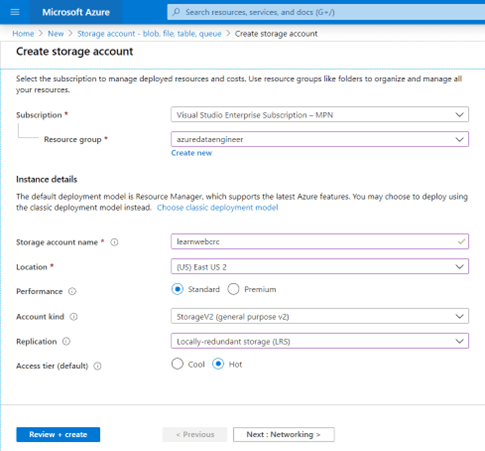
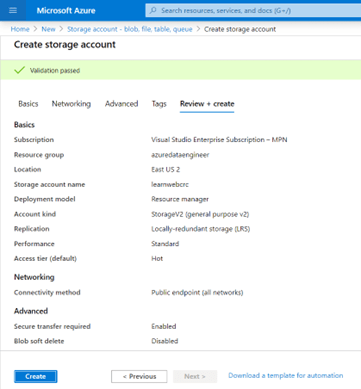
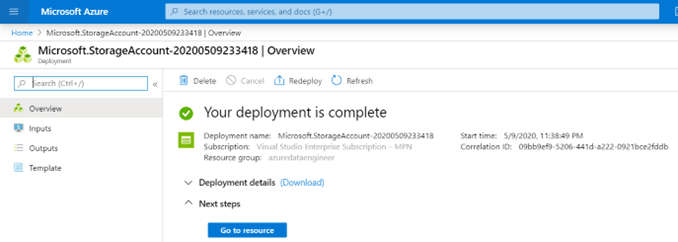
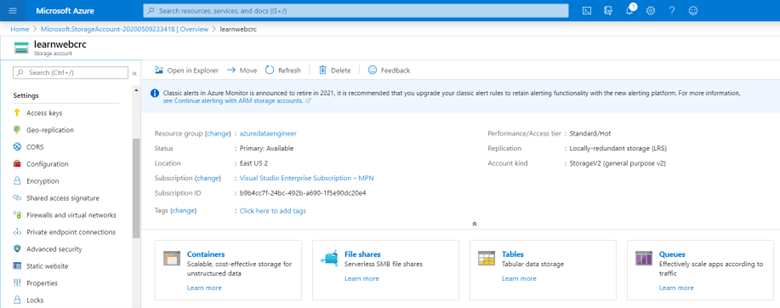
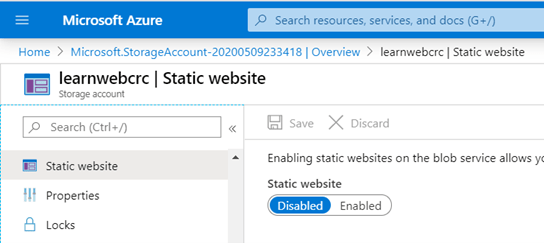
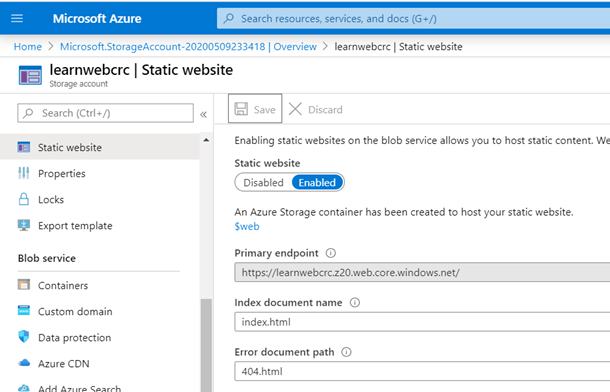
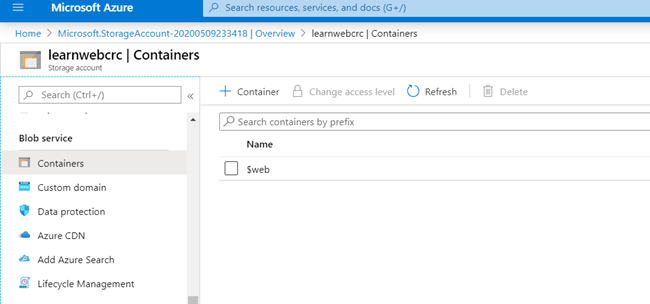
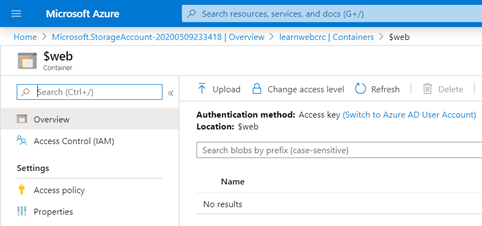
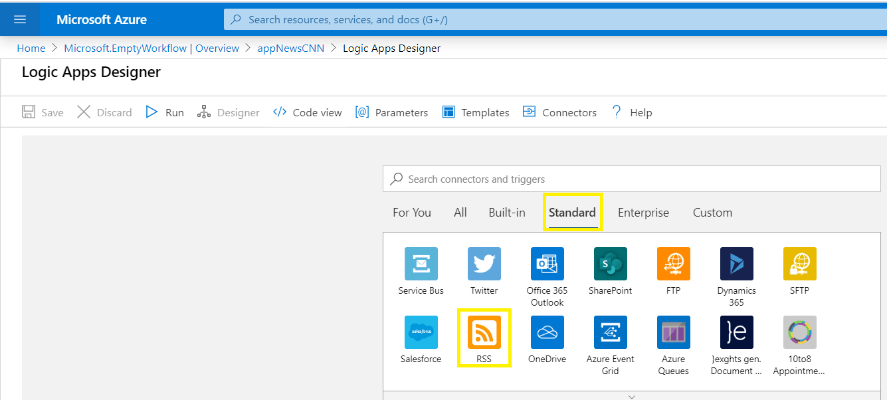
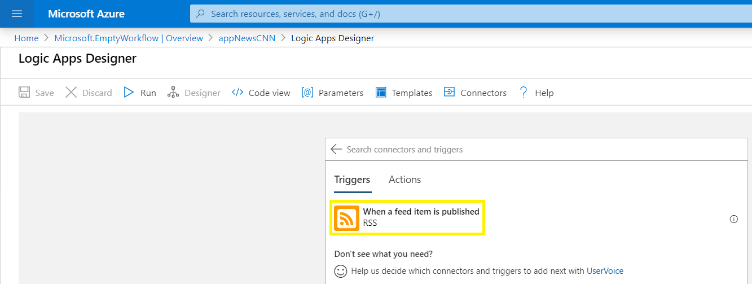
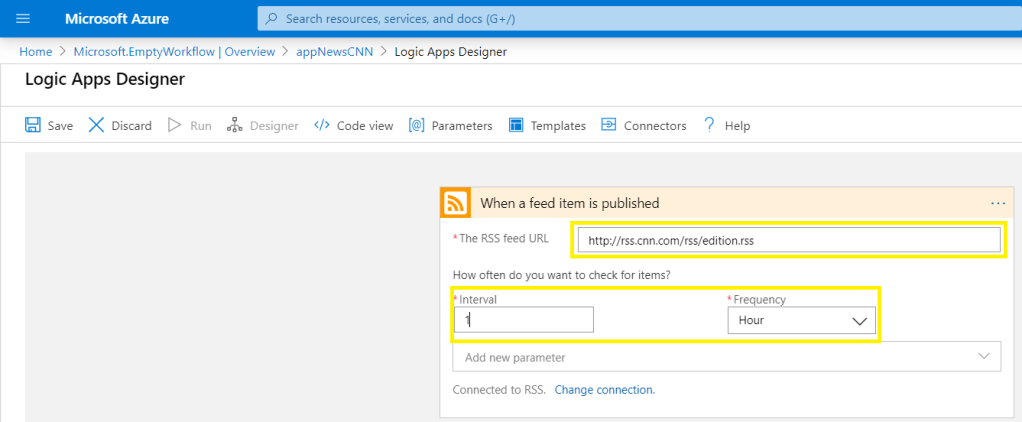
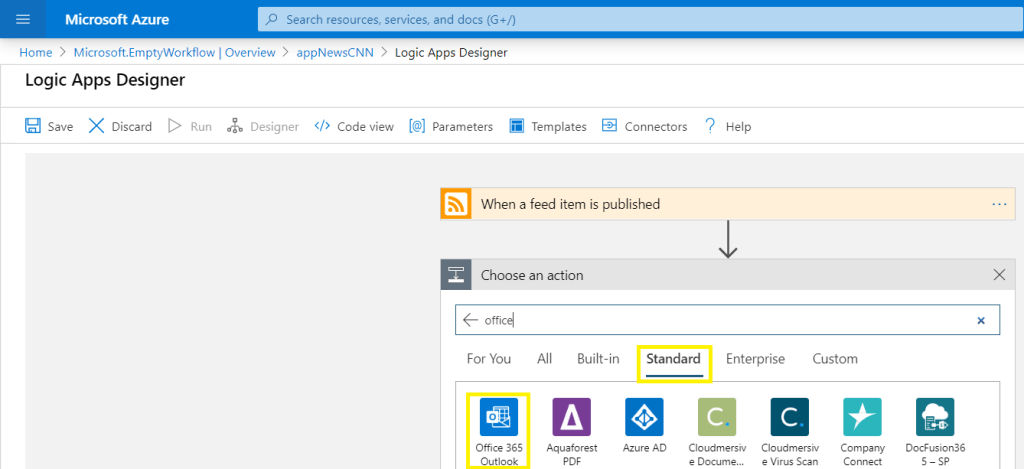
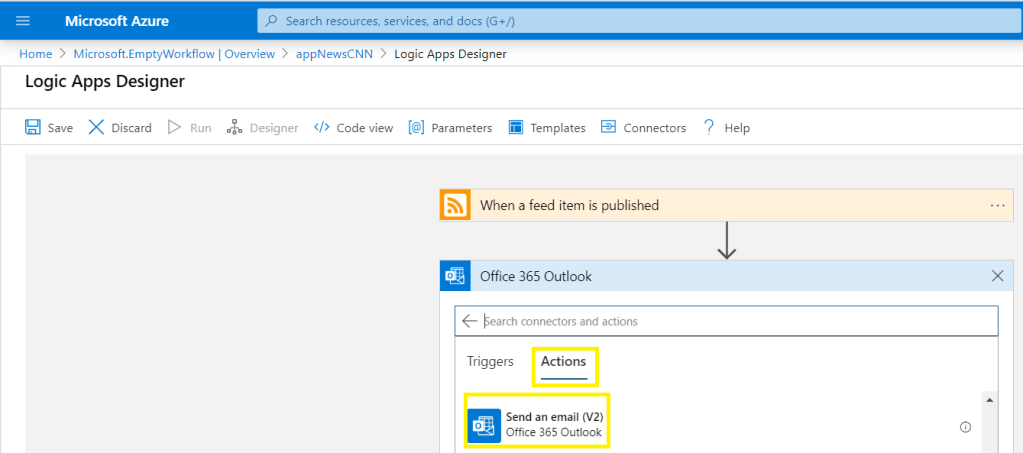
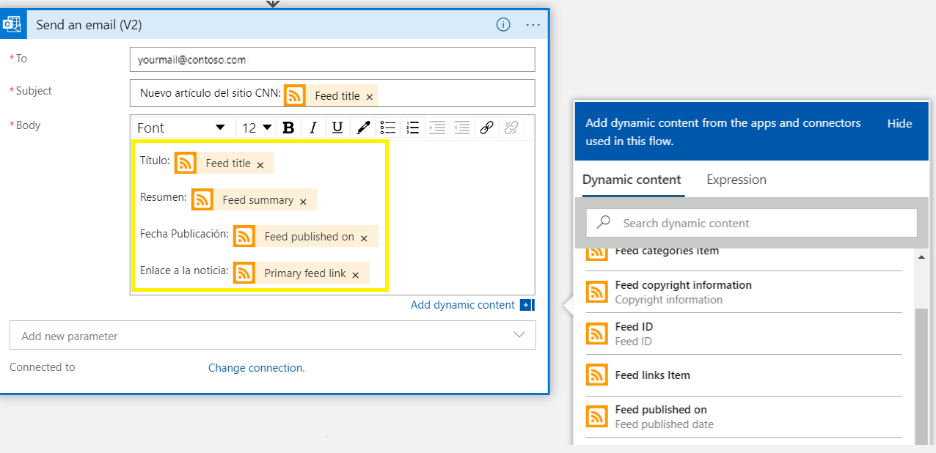
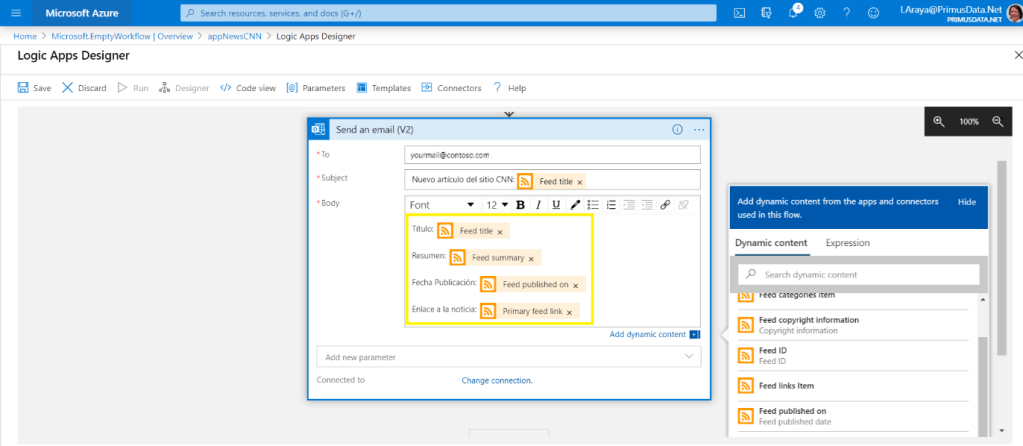
En febrero de 2024, las comunidades de datos centroamericanas atendimos el llamado de nuestros amigos en Nicaragua e iniciamos un evento cuyo fin es llevar conocimiento a nuestra región, impulsar el intercambio de ideas, la colaboración y el crecimiento en el ámbito digital. Un evento que brindara una experiencia de transformación digital a nuestros países, y así lo hicimos en Managua, Nicaragua.
Este año, nuestro país, Costa Rica, será la sede de la segunda edición de la Jornada, y estamos entusiasmados de poder tener esta celebración a muy pocos días: #SJODigital2025, un evento que se llevará a cabo del 15 al 17 de mayo del 2025.
Y es que siempre asistir a un evento, para quienes disfrutamos del aprendizaje continuo, es una gran oportunidad: conocer y compartir con personas, fortalecer conocimientos, captar nuevas ideas, aprender a resolver situaciones, descubrir herramientas y tendencias del mercado, usualmente acompañadas por casos de uso reales que los oradores muy amablemente comparten con el público.
Asistir a un evento, ya sea virtual o presencial, implica invertir algo muy valioso: nuestro tiempo. Siempre requiere un esfuerzo, pero en el caso de los eventos presenciales, ese esfuerzo suele ser mayor: hay que elegir la vestimenta, cubrir gastos de traslado, alimentación, así como resolver aspectos logísticos. Sin embargo, más allá de lo práctico, muchas veces no somos del todo conscientes del costo real de estar allí presentes: dejar de trabajar, sacrificar tiempo libre, familiar o de descanso. Aun así, elegimos hacerlo porque entendemos que vale la pena: asistimos para “afilar el hacha”, mantenernos actualizados, invertir en nuestro desarrollo profesional y tomar mejores decisiones en el día a día. En un campo como la tecnología, donde el cambio es constante, sabemos que aprender no es opcional, sino una necesidad diaria.
Entonces, mientras estamos en un evento, vale la pena preguntarnos: ¿realmente lo estamos aprovechando? ¿Qué tanta atención le estamos prestando a lo que sucede frente a nosotros? Al contenido, al mensaje, a quien nos comparte una idea, una solución, una herramienta, a ese sinfín de conocimientos que hoy están al alcance gracias a la posibilidad de asistir.
¿Le ha pasado que está en una charla y, de pronto, siente la necesidad de revisar el celular porque vibró o apareció una notificación? Lo toma, ve de qué se trata, piensa un momento en eso, y sin darse cuenta empieza a divagar. Cuando intenta volver a concentrarse, ya ha perdido el hilo de lo que estaba pasando. ¿Será que realmente podemos hacer varias cosas a la vez? La verdad es que no. Somos monotarea.
¿Y qué podemos hacer para retener mejor el mensaje?
- Tome nota: haz un resumen, un mapa mental o conceptual.
- Pida la presentación: a veces se pierde tiempo tomando fotos o anotando textualmente lo que se muestra. Si te pueden compartir el material, te podés enfocar en escuchar.
- Minimizá los distractores: guarda el celular en el bolso o colócalo en modo avión. Al terminar la sesión, ya tendrás tiempo para revisarlo.
¿Importa dónde me siento?
¡Sí! Cuanto más adelante te ubiques, mayor será tu nivel de atención. Sentarse atrás trae más distracciones (y más chance de conversar con alguien que no vino con el mismo objetivo 😅).
Recuerda que estás compartiendo el espacio con personas que, probablemente, comparten tus valores, pasiones o intereses. ¡Conecta con ellas! Intercambia contactos, pedí su LinkedIn o WhatsApp. Generar vínculos también es parte de la experiencia; cultivar relaciones genuinas en estos espacios puede abrir puertas inesperadas.
¿Y después del evento?
¿Qué haces con lo que aprendiste? ¿Con tus notas? ¿Cómo lo incorporas?
Dicen que “los dedos tienen buena memoria”, y es muy cierto. Deja pasar un par de días y luego escribí lo que aprendiste sin ver tus notas.
Por ejemplo:
"En SJODigital tuve la oportunidad de asistir a varios espacios muy enriquecedores. Comencé con el taller de Journey Mapping, donde aprendí a mapear el recorrido del cliente en procesos de transformación digital. También participé en una charla sobre cómo integrar Power BI con el lenguaje R, lo cual abre nuevas posibilidades analíticas.
Exploré estrategias para el éxito empresarial y conocí una solución de automatización inteligente de procesos que podría adaptarse muy bien a nuestra organización. Asistí a una charla sobre los desafíos y realidades de la inteligencia artificial, que nos invitó a reflexionar sobre cómo aprovecharla desde nuestras propias realidades.
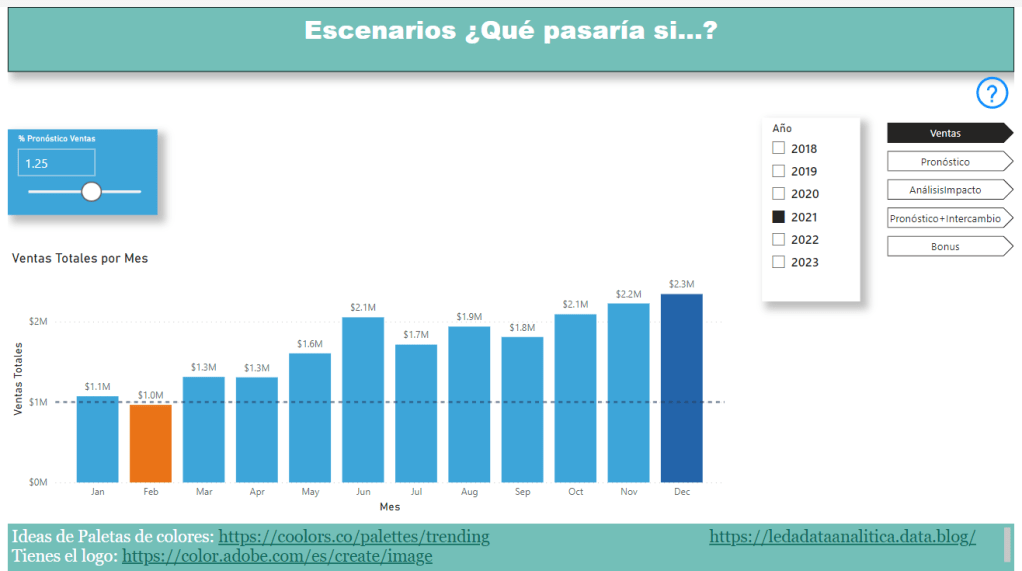
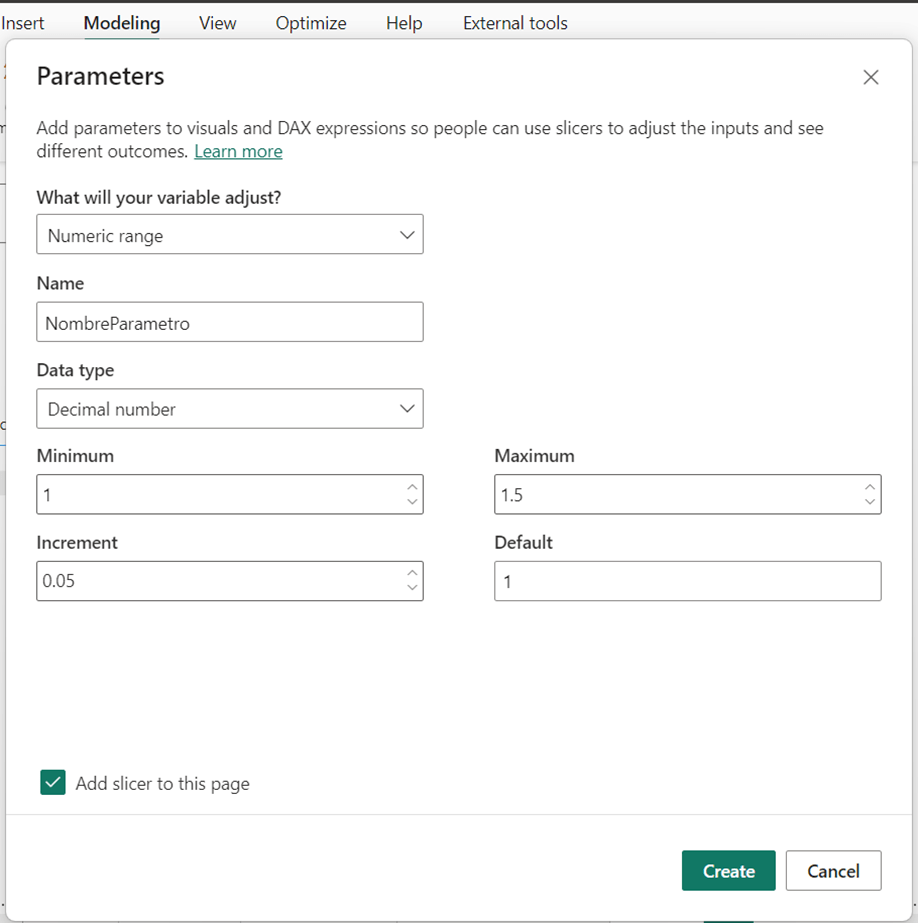
Otra sesión que me pareció especialmente valiosa fue sobre cómo transformar los documentos que usamos a diario en decisiones inteligentes. Dado el volumen de documentos que generamos, podríamos estar dejando pasar oportunidades importantes. Finalmente, participé en una charla sobre innovación visual, donde comprendí cómo potenciar el impacto de los objetos visuales nativos de Power BI y transformarlos de forma dinámica para mejorar la interacción del usuario con los datos de nuestra organización.
(Por cierto, todos estos temas sí estarán en el evento 😉)
Ese ejercicio de repaso te ayuda a identificar qué realmente se te quedó. Luego preguntate:
- ¿Cómo puedo aplicar esto en mi día a día?
Si no se aplica, se olvida. - ¿Sientes que no tienes a quién enseñárselo?
Escríbalo en su blog, en un post, o hasta en su cuaderno. Enseñar es la mejor forma de aprender. Si lo enseñas, lo incorporas.
Asistir a un evento es una inversión. Pero si solo vas, prestas atención y no aplicas nada, o no conoces a nadie, no hablas con nadie aparte de tu grupo, te estás perdiendo gran parte de la experiencia.
¿Te quedaron dudas en una charla? ¿No hubo oportunidad de preguntar?
Conoce a los ponentes: búscalos durante el evento o escríbeles por redes sociales. La mayoría suele compartir sus datos de contacto durante la presentación. No te quedes con la espina: tanto los ponentes nacionales como los internacionales estarán encantados de conocer tus inquietudes. A veces, el tiempo durante la charla no alcanza para responder todas las preguntas.
Bonus: ¡Sacá la foto!
El selfie está bien, ¡es magnífico! Pero más importante que eso es todo el conocimiento que te llevás. Lo que sucede después puede convertirse en una cadena de eventos afortunados.
Participar activamente en un evento no es casualidad, es un acto de intencionalidad:
invertir tiempo hoy para crecer mañana.
¿Le ha pasado algo parecido? Cuéntame en los comentarios qué estrategias utilizas para sacar el máximo provecho de un evento o si alguna vez sentiste que podrías haber hecho algo diferente.

 Ingeniería de Datos (Data Engineering)
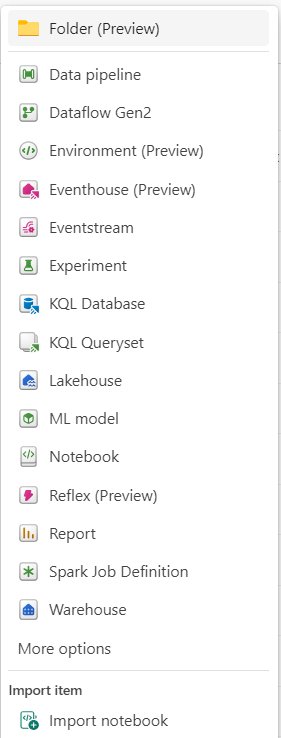
Ingeniería de Datos (Data Engineering) Almacén de Lago (Lakehouse): Almacena big data para procesos de limpieza, consultas, reportes y para compartir datos. Permite el almacenamiento de datos estructurados y no estructurados en una misma ubicación.
Almacén de Lago (Lakehouse): Almacena big data para procesos de limpieza, consultas, reportes y para compartir datos. Permite el almacenamiento de datos estructurados y no estructurados en una misma ubicación. Cuaderno (Notebook): Facilita el desarrollo de trabajos Spark y experimentos de Machine Learning. Los lenguajes soportados incluyen PySpark (Python), Spark (Scala), Spark SQL y Spark R.
Cuaderno (Notebook): Facilita el desarrollo de trabajos Spark y experimentos de Machine Learning. Los lenguajes soportados incluyen PySpark (Python), Spark (Scala), Spark SQL y Spark R. Definición de Trabajo Spark (Spark Job Definition): Permite enviar trabajos a clústeres Spark, además de definir, programar y gestionar trabajos para el procesamiento de big data.
Definición de Trabajo Spark (Spark Job Definition): Permite enviar trabajos a clústeres Spark, además de definir, programar y gestionar trabajos para el procesamiento de big data. Data Factory
Data Factory Canalizaciones (Data Pipeline): Orquesta las tareas de ingestión y transformación de datos.
Canalizaciones (Data Pipeline): Orquesta las tareas de ingestión y transformación de datos. Flujo de Datos (Dataflow Gen2): Permite preparar, limpiar y transformar datos en un flujo interno o almacenamiento temporal, al cual se puede acceder mediante un conector de tipo Dataflow.
Flujo de Datos (Dataflow Gen2): Permite preparar, limpiar y transformar datos en un flujo interno o almacenamiento temporal, al cual se puede acceder mediante un conector de tipo Dataflow. Data Warehouse
Data Warehouse Bodega de Datos (Warehouse): Proporciona almacenamiento transaccional compatible con DDL y DML. Soporta métodos de ingestión como COPY INTO, Pipelines, Dataflows o consultas como CREATE TABLE AS SELECT, INSERT o SELECT INTO.
Bodega de Datos (Warehouse): Proporciona almacenamiento transaccional compatible con DDL y DML. Soporta métodos de ingestión como COPY INTO, Pipelines, Dataflows o consultas como CREATE TABLE AS SELECT, INSERT o SELECT INTO. Power BI
Power BI Reporte (Report): Crea informes interactivos para presentar los datos.
Reporte (Report): Crea informes interactivos para presentar los datos. Reporte Paginado (Paginated Report): Permite el despliegue tabular de datos en un informe, facilitando la impresión y la descarga.
Reporte Paginado (Paginated Report): Permite el despliegue tabular de datos en un informe, facilitando la impresión y la descarga. Tarjeta de Puntuación (Scorecard): Define, rastrea y comparte métricas clave para la organización. También ayuda a establecer objetivos y dar seguimiento al desempeño del negocio.
Tarjeta de Puntuación (Scorecard): Define, rastrea y comparte métricas clave para la organización. También ayuda a establecer objetivos y dar seguimiento al desempeño del negocio. Panel de Control (Dashboard): Construye una página que cuenta una historia de datos a través de visualizaciones.
Panel de Control (Dashboard): Construye una página que cuenta una historia de datos a través de visualizaciones. Almácén de Datos (Datamart) (preview): Solución analítica de autoservicio que permite a los usuarios almacenar y explorar datos cargados en una base de datos completamente gestionada, enfocada en el negocio o en datos departamentales.
Almácén de Datos (Datamart) (preview): Solución analítica de autoservicio que permite a los usuarios almacenar y explorar datos cargados en una base de datos completamente gestionada, enfocada en el negocio o en datos departamentales. Análisis en Tiempo Real (Real Time Analytics)
Análisis en Tiempo Real (Real Time Analytics) KQL Database: Herramienta de integración que permite gestión y análisis de datos para análisis en tiempo real.
KQL Database: Herramienta de integración que permite gestión y análisis de datos para análisis en tiempo real. KQL Queryset: Permite ejecutar consultas y vistas sobre bases de datos KQL utilizando Kusto Query Language, y también soporta algunas funciones SQL.
KQL Queryset: Permite ejecutar consultas y vistas sobre bases de datos KQL utilizando Kusto Query Language, y también soporta algunas funciones SQL. Eventhouse (preview): Gestiona múltiples bases de datos simultáneamente, compartiendo capacidad y recursos para optimizar el rendimiento y los costos.
Eventhouse (preview): Gestiona múltiples bases de datos simultáneamente, compartiendo capacidad y recursos para optimizar el rendimiento y los costos. Eventstream: Función centralizada que captura, transforma y enruta eventos en tiempo real hacia diversos destinos sin requerir código. Se integra con Azure Event Hubs, bases de datos KQL y Lakehouses.
Eventstream: Función centralizada que captura, transforma y enruta eventos en tiempo real hacia diversos destinos sin requerir código. Se integra con Azure Event Hubs, bases de datos KQL y Lakehouses. Ciencia de Datos (Data Science)
Ciencia de Datos (Data Science) Modelo ML (ML Model): Utiliza modelos de Machine Learning para predecir resultados y detectar anomalías en los datos.
Modelo ML (ML Model): Utiliza modelos de Machine Learning para predecir resultados y detectar anomalías en los datos. Experimento (Experiment): Permite crear, ejecutar y realizar un seguimiento del desarrollo de múltiples modelos para validar hipótesis.
Experimento (Experiment): Permite crear, ejecutar y realizar un seguimiento del desarrollo de múltiples modelos para validar hipótesis. Data Activator
Data Activator Reflex (Preview): Monitorea datos en Power BI y Eventstream. Cuando los datos cumplen ciertos umbrales o coinciden con patrones específicos, toma automáticamente acciones como enviar alertas o iniciar flujos de trabajo en Power Automate.
Reflex (Preview): Monitorea datos en Power BI y Eventstream. Cuando los datos cumplen ciertos umbrales o coinciden con patrones específicos, toma automáticamente acciones como enviar alertas o iniciar flujos de trabajo en Power Automate. Soluciones de Industria (Industry Solutions)
Soluciones de Industria (Industry Solutions) Sostenibilidad (Sustainability Solutions): Facilitan la ingesta, estandarización y análisis de datos ambientales, sociales y de gobernanza.
Sostenibilidad (Sustainability Solutions): Facilitan la ingesta, estandarización y análisis de datos ambientales, sociales y de gobernanza. Comercio Minoristas (Retail Solutions): Ayudan a gestionar grandes volúmenes de datos, integrar información de diversas fuentes y proporcionar análisis en tiempo real. Los minoristas pueden utilizar estas soluciones para optimizar inventarios, segmentar clientes, prever ventas, establecer precios dinámicos y detectar fraudes.
Comercio Minoristas (Retail Solutions): Ayudan a gestionar grandes volúmenes de datos, integrar información de diversas fuentes y proporcionar análisis en tiempo real. Los minoristas pueden utilizar estas soluciones para optimizar inventarios, segmentar clientes, prever ventas, establecer precios dinámicos y detectar fraudes. Salud (Healthcare Solutions): Están diseñadas para acelerar el tiempo de creación de valor para los clientes, abordando la necesidad crítica de transformar datos relacionados con la salud de manera eficiente a un formato adecuado para el análisis.
Salud (Healthcare Solutions): Están diseñadas para acelerar el tiempo de creación de valor para los clientes, abordando la necesidad crítica de transformar datos relacionados con la salud de manera eficiente a un formato adecuado para el análisis.